- Introduction
- Le réseau pour les conteneurs
- Lien avec le Kubelet
- Installons enfin notre plugin CNI
- Prochaine étape
A la fin de la mise en place des masters nous avions un cluster contenant un node master avec un statut NotReady, ceci dû à l’absence d’un add-on réseau.
Cette article va donc traiter de ce point.
Introduction
Afin que les pods puissent communiquer entre eux l’installation d’un plugin réseau est nécessaire. Dans la majorité des cas, un plugin CNI est utilisé.
CNI et plugin CNI
Par abus de language on entend plus souvent le terme CNI, mais il faudrait plutôt parler de plugin CNI.
En effet, un plugin CNI implémente la spécification Container Network Interface (ou CNI) et va être en charge de configurer le réseau d’un conteneur.
Mais avant la mise en place de ce dernier, revenons d’abord sur la notion de réseau au sein d’un conteneur
Le réseau pour les conteneurs
Les conteneurs ne sont rien d’autres que des processus avec une vision restreinte.
Cette isolation est basée sur des mécanisques du noyau Linux que sont les namespaces et les cgroups.
Pour le réseau nous allons nous intéresser aux premiers : les namespaces.
Ces derniers permettent au système d’exploitation de limiter ce qu’un processus peut voir.
Différents types de namespaces sont disponibles :
- pid
- mnt
- ipc
- net
- uts
- user
- cgroup
- time
Vous l’aurez deviné pour l’isolation du réseau, c’est le namespace réseau (net) qui est utilisé 😉
Il virtualise la pile réseau permettant à chaque namespace d’avoir ses adresses IP, sa table de routage, sa table ARP, ses sockets, etc.
Cas pratique : communication entre deux namespaces
On crée 2 net namespaces
ip netns add c1
ip netns add c2
Pour le moment il n’y a que l’interface réseau loopback présentes dans ces derniers
$ ip netns exec c1 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
$ ip netns exec c2 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
Comme on le ferait pour connecter deux ordinateurs, on va utiliser un câble.
Nous allons relier les deux net namespaces par un câble “virtuel” (plus exactement par un lien de type veth pour Virtual Ethernet).
On crée le câble virtuel, où l’on précise les noms des deux extrémités : vethc1 et vethc2
ip link add vethc1 type veth peer vethc2
On attache une extrémité (une interface réseau) à chaque net namespaces
ip link set veth-c1 netns c1
ip link set veth-c2 netns c2
On configure ensuite les interfaces réseaux avec leurs adresses IP
ip netns exec c1 ip addr add 192.168.0.1 dev vethc1
ip netns exec c1 ip link set vethc1 up
ip netns exec c2 ip addr add 192.168.0.2 dev vethc2
ip netns exec c2 ip link set vethc2 up
On spécifie enfin une route vers le réseau 192.168.0.0/24
ip netns exec c1 ip route add 192.168.0.0/24 dev vethc1
ip netns exec c2 ip route add 192.168.0.0/24 dev vethc2
Maintenant, si on liste les interfaces réseaux de c1, on en retrouve deux
$ ip netns exec c1 ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: vethc1@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 36:6b:a1:8e:bb:4c brd ff:ff:ff:ff:ff:ff link-netns c2
inet 192.168.0.1/32 scope global vethc1
valid_lft forever preferred_lft forever
inet6 fe80::346b:a1ff:fe8e:bb4c/64 scope link
valid_lft forever preferred_lft forever
Et si on éxecute un ping depuis c1 depuis c2 : la connexion est établie
$ ip netns exec c1 ping 192.168.0.2 -c3
PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data.
64 bytes from 192.168.0.2: icmp_seq=1 ttl=64 time=0.096 ms
64 bytes from 192.168.0.2: icmp_seq=2 ttl=64 time=0.046 ms
64 bytes from 192.168.0.2: icmp_seq=3 ttl=64 time=0.029 ms
--- 192.168.0.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2046ms
rtt min/avg/max/mdev = 0.029/0.057/0.096/0.028 ms
Nous venons de créer une connexion entre deux net namespaces (transposable à des conteneurs) dont voici le schéma récapitulatif

Que se passerait-il si nous voulions ajouter un nouveau conteneur ?
Cas pratique : communication entre plusieurs conteneurs
Dans le cas où nous voulons ajouter un nouveau conteneur : c3 par exemple, il faudrait
- créer 2 câbles virtuels :
c3-c1etc3-c2 - réaliser des opérations de configuration
- affectation d’une adresse IP
- ajout d’une route vers le réseau
192.168.0.0/24
Et ainsi de suite pour un chaque nouveau conteneur. Cela devient vite complexe à gérer pour, par exemple 5, 10, 15 conteneurs… 🤯
Reprenons le parallèle avec du matériel physique : comment connecter plusieurs ordinateurs ? Tout simplement avec un switch 😁
Switch “virtuel”
Nous allons donc créer un switch “virtuel” et connecter chaque net namespace à ce dernier, permettant aux net namespaces de communiquer entre eux.
Création du switch “virtuel”
ip link add vswitch type bridge
ip link set dev vswitch up
-
En utilisant
brctlnous pouvons connaître l’état du switch$ brctl show vswitch bridge name bridge id STP enabled interfaces vswitch 8000.000000000000 no
Création de 2 net namespaces
ip netns add c10
ip netns add c11
Création des “câbles” afin de connecter ces derniers au switch virtuel
ip link add vethc10 type veth peer vethc10-vswitch
ip link add vethc11 type veth peer vethc11-vswitch
Attachons maintenant les extrémités des “câbles” entre les net namespaces et le switch
ip link set vethc10 netns c10
ip link set vethc10-vswitch master vswitch
ip link set vethc10-vswitch up
ip link set vethc11 netns c11
ip link set vethc11-vswitch master vswitch
ip link set vethc11-vswitch up
Nous pouvons voir que ces derniers sont maintenant présents sur le swicth
/home/vagrant# brctl show vswitch
bridge name bridge id STP enabled interfaces
vswitch 8000.1a5e598dcc6c no vethc10-vswitch
vethc11-vswitch
Configuration des adresses IP
ip netns exec c10 ip addr add 192.168.0.10 dev vethc10
ip netns exec c10 ip link set vethc10 up
ip netns exec c11 ip addr add 192.168.0.11 dev vethc11
ip netns exec c11 ip link set vethc11 up
Et enfin on spécifie les routes vers le réseau 192.168.0.0/24 dans chaque net namespaces
ip netns exec c10 ip route add 192.168.0.0/24 dev vethc10
ip netns exec c11 ip route add 192.168.0.0/24 dev vethc11
Testons la connexion entre les net namespaces : la connexion est établie
$ ip netns exec c10 ping 192.168.0.11 -c3
PING 192.168.0.11 (192.168.0.11) 56(84) bytes of data.
64 bytes from 192.168.0.11: icmp_seq=1 ttl=64 time=0.022 ms
64 bytes from 192.168.0.11: icmp_seq=2 ttl=64 time=0.052 ms
64 bytes from 192.168.0.11: icmp_seq=3 ttl=64 time=0.052 ms
--- 192.168.0.11 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2037ms
rtt min/avg/max/mdev = 0.022/0.042/0.052/0.014 ms
Ajout d’un nouveau conteneur
Maintenant si nous voulons rajouter un nouveau namespace (c12), il suffit de créer une connexion entre son namespace et le switch
ip netns add c12
ip link add vethc12 type veth peer vethc12-vswitch
ip link set vethc12 netns c12
ip link set vethc12-vswitch master vswitch
ip link set vethc12-vswitch up
ip netns exec c12 ip addr add 192.168.0.12 dev vethc12
ip netns exec c12 ip link set vethc12 up
ip netns exec c12 ip route add 192.168.0.0/24 dev vethc12
Testons alors les connections entre les conteneurs
-
depuis
c10versc12: la connexion est établie$ ip netns exec c10 ping 192.168.0.12 -c3 PING 192.168.0.12 (192.168.0.12) 56(84) bytes of data. 64 bytes from 192.168.0.12: icmp_seq=1 ttl=64 time=0.043 ms 64 bytes from 192.168.0.12: icmp_seq=2 ttl=64 time=0.036 ms 64 bytes from 192.168.0.12: icmp_seq=3 ttl=64 time=0.040 ms --- 192.168.0.12 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2048ms rtt min/avg/max/mdev = 0.036/0.039/0.043/0.003 ms -
depuis
c12versc10: la connexion est établie$ ip netns exec c12 ping 192.168.0.10 -c3 PING 192.168.0.10 (192.168.0.10) 56(84) bytes of data. 64 bytes from 192.168.0.10: icmp_seq=1 ttl=64 time=0.022 ms 64 bytes from 192.168.0.10: icmp_seq=2 ttl=64 time=0.054 ms 64 bytes from 192.168.0.10: icmp_seq=3 ttl=64 time=0.041 ms --- 192.168.0.10 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2052ms rtt min/avg/max/mdev = 0.022/0.039/0.054/0.013 ms
Récapitulatif et parallèle
Voici ce que nous venons de réaliser :
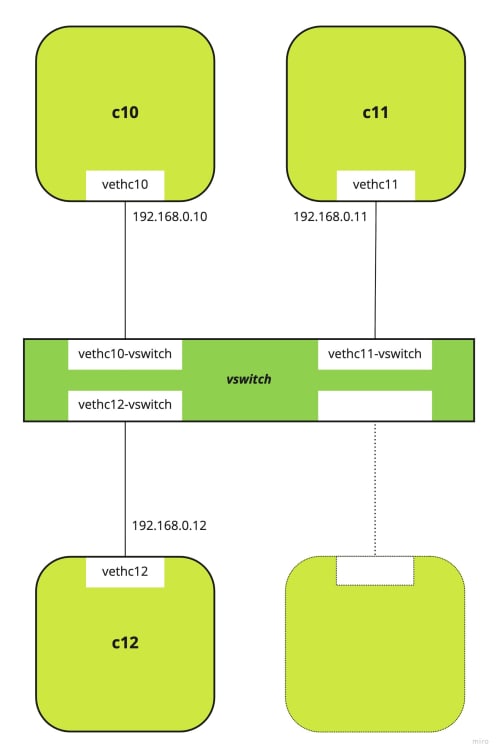
Mais cela me dit quelque chose… 🤔
Si je remplace vswitch par docker0 puis que je démarre deux conteneurs nginx…
$ brctl show docker0
bridge name bridge id STP enabled interfaces
docker0 8000.024221143511 no
$ docker run -d nginx
$ docker run -d nginx
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
55507ec3aa5b nginx "/docker-entrypoint.…" 28 seconds ago Up 27 seconds 80/tcp tender_haslett
1d026b03a863 nginx "/docker-entrypoint.…" 55 seconds ago Up 54 seconds 80/tcp brave_hypatia
$ brctl show docker0
bridge name bridge id STP enabled interfaces
docker0 8000.024221143511 no veth746347e
vethfb7d5c0
Il s’agit du même modèle utilisé par docker pour gérer les réseaux de type bridge1
Continuons notre découverte : accès externe et communication inter-nodes
Accès externe
A ce stade, les net namespaces peuvent communiquer entre eux mais pas vers l’extérieur.
Sans rentrer dans les détails, voici une façon de configurer cela :
Sur l’hôte
- affectation d’une IP à l’interface
vswitch: par exemple192.168.1.1 - ajout d’une route vers le réseau des
net namespaces(192.168.1.0/24) viavswitch - activation de l’IP Forwarding afin que le noeud se comporte comme un routeur
- ajout d’une règle IP Masquerade pour le traffic sortant du réseau
192.168.0.0/24
Dans chaques net namespaces
- ajout de la route par défaut via l’IP du vswitch :
192.168.1.1
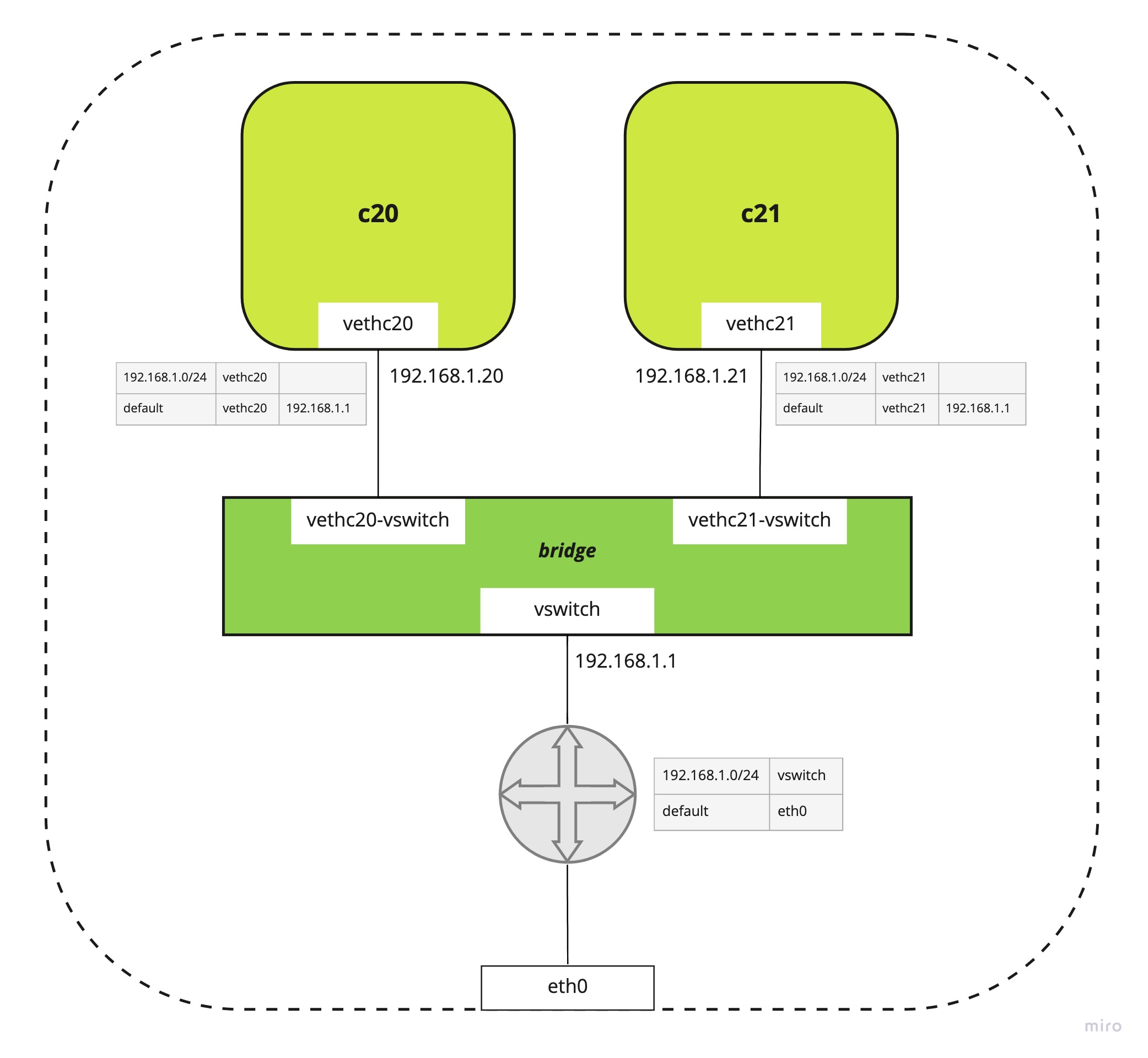
Communication inter-nodes
A cet instant les conteneurs d’un noeud peuvent communiquer entre eux et vers l’extérieur.
Quand est-il pour faire communiquer des net namespaces entre plusieurs noeuds et donc se rapprocher du modèle d’un cluster Kubernetes où les pods communiquent entre eux peu importe leur localisation dans ce dernier.
Implémentation “basique”
Voici un schéma de la configuration pour une communication entre 2 noeuds
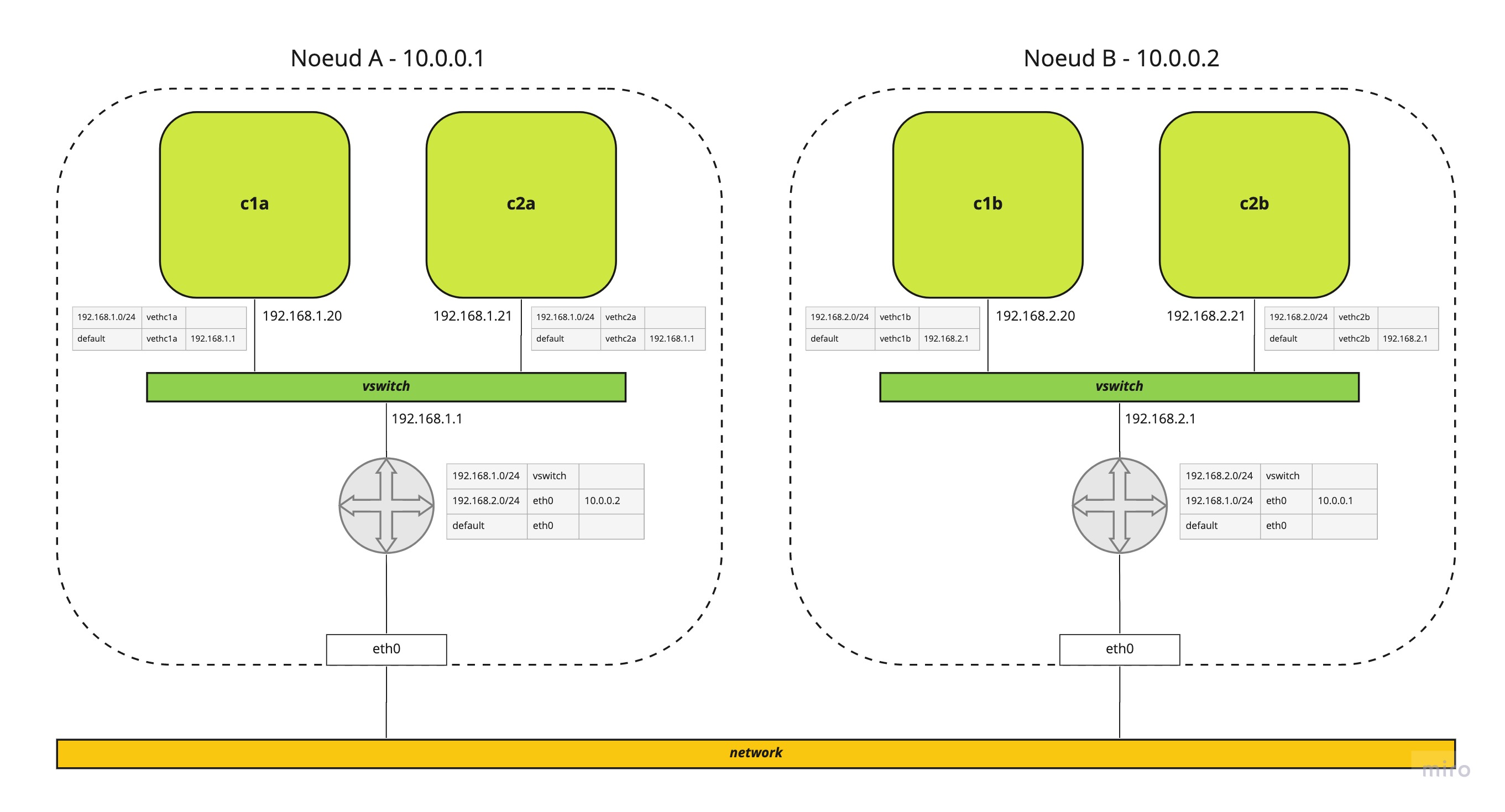
Pour les deux noeuds nous avons une configuration similaire à précédemment
- un
vswitchsur chaque noeud - des
net namespaces- configurés sur le noeud A dans le réseau
192.168.1.0/24 - configurés sur le noeud B dans le réseau
192.168.2.0/24
- configurés sur le noeud A dans le réseau
- des règles de routage
- sur le noeud A une route vers
192.168.2.0/24via le noeud B - sur le noeud B une route vers
192.168.1.0/24via le noeud A
- sur le noeud A une route vers
Ceci est un exemple d’une implémentation “basique” de la configuration réseau.
Imaginez reproduire toutes ces étapes de configuration pour chaque net namespace et chaque noeud dans le cadre d’un cluster Kubernetes où tout est éphémère (les pods, les nodes, etc) 😳
Le but d’un plugin CNI est de réaliser toutes ses opérations à votre place !
Lien avec le Kubelet
Un plugin CNI est un éxecutable qui implémente la spécification CNI.
Dans cette dernière parmi les commandes à implémenter, les deux plus “importantes” sont :
ADDqui ajoute un conteneur dans un réseauDELETEqui supprime un conteneur d’un réseau
Le plugin CNI est invoqué par l’orchestrateur. Dans le cas de Kubernetes, le plugin CNI est appelé par le Kubelet.
Voici un resumé des étapes que Kubelet effectue pour ajouter un nouveau pod
- création d’un
net namespacepour le nouveau pod - appel de l’opération
ADDdu plugin CNI - le plugin CNI interroge l’API Kubernetes afin de déterminer les options de configuration requises par le nouveau pod
- le plugin CNI demande une adresse IP (ceci est généralement réalisé via un plugin IPAM)
- le plugin CNI crée le “câble” entre le
net namespacedu conteneur et leroot net namespace, puis met en place la configuration réseau adéquate (routage, etc) - le plugin CNI renvoie au Kubelet l’IP et le
net namespacecrées - le Kubelet associe le conteneur dans le bon
net namespaceet va poursuivre la création du pod
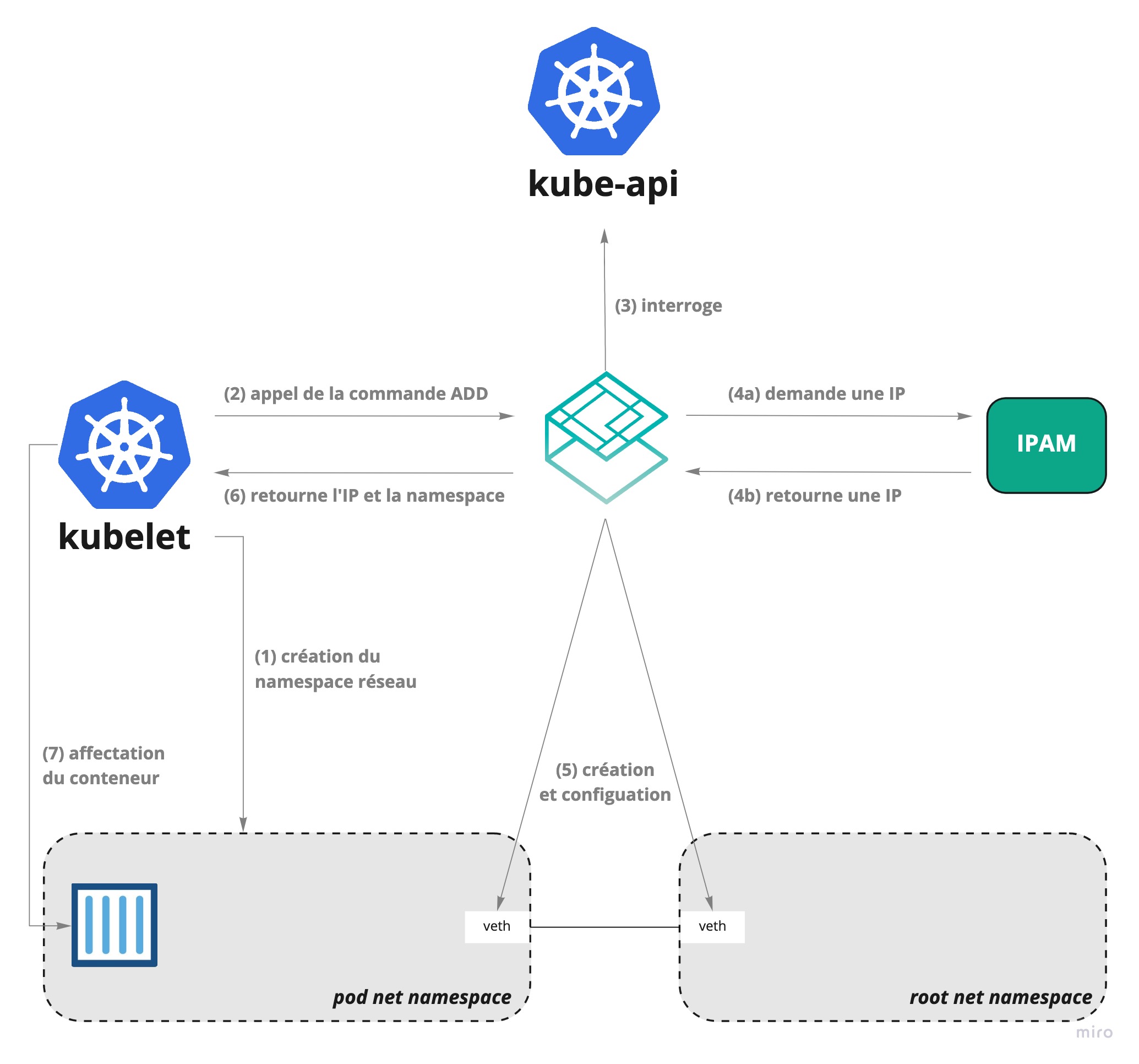
Installons enfin notre plugin CNI
Le but premier de cet article est d’installer un plugin CNI dans mon cluster, mais pourquoi évoquer les éléments de la mise en place du réseau entre des conteneurs ?
Tout d’abord pour comprendre pourquoi il existe autant de plugins CNI.
Je pourrais par exemple citer Weave-Net, Flannel, Calico, Cilium, ou Antrea. 2
Leur fonction de base est la même, mais la façon d’implémenter la mise en place du réseau est différente :
Calicoutilise le protocole BGP pour distribuer les routes entre les noeuds du clusterAntrease base sur Open vSwitch pour créer le “switch virtuel” et dispose donc de toutes les fonctionnalités d’OVSAzure CNIpré-alloue les IPs d’un Azure Subnet pour les pods d’un noeud et n’a pas besoin d’ajouter des règles de routageCiliumse base sur eBPF.- etc.
Affirmer qu’un plugin CNI est meilleur qu’un autre est un constat difficile. Chaque plugin à ses spécificités et peut répondre à un besoin différent.
Et là je n’aborde pas la possibilité de chainer les plugins CNI 😉
Mon choix
Dans mon cas mes critères importants sont
- le support des Networks Policies
- la simplicité de mise en place
- la communauté présente autour du plugin
J’ai hésité entre Calico et Cilium, pour finalement choisir le second.
Outre le fait que Cilium commence de plus en plus à être adopté par différents acteurs du cloud3 4 et que Calico semble être plus performant5, j’ai été séduit par sa capacité à fournir de la visibilité sur le trafic réseau.
Je suis fortement convaincu qu’un système qui n’est pas observable est très difficile à gérer et à faire évoluer. Et cela est encore plus vrai dans le monde de Kubernetes.
Avoir la possibilité de mettre en place au plus tôt des outils permettant de comprendre mon infrastructure est donc important pour moi : Cilium apporte et étend ces possibilités via Hubble.
Installation
Une section dédiée à l‘installation de Cilium avec kubeadm est présente dans la documentation officielle : cette dernière utilise Helm 3.
Voici les instructions que j’ai utilisées :
helm repo add cilium https://helm.cilium.io/
helm repo update
helm install cilium cilium/cilium \
--version 1.9.3 \
--namespace kube-system \
--set kubeProxyReplacement=disabled \
--set k8sServiceHost=10.9.1.11 \
--set k8sServicePort=6443
Par rapport à l’installation par “défaut”, on trouve quelques options supplémentaires :
kubeProxyReplacement=disabled: désactive le remplacement dekube-proxypar Ciliumk8sServiceHost=10.9.1.11: spécifie l’adresse IP de l'api-serverde Kubernetesk8sServicePort=6443: spécifie le port IP de l'api-serverde Kubernetes
Après quelques minutes, examions les pods et les noeuds :
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system cilium-hlsmd 1/1 Running 0 83s 10.9.1.11 k8s-m01 <none> <none>
kube-system cilium-operator-66bb9d8b9d-4rgng 1/1 Running 0 83s 10.9.1.11 k8s-m01 <none> <none>
kube-system cilium-operator-66bb9d8b9d-5jm8f 0/1 Pending 0 83s <none> <none> <none> <none>
kube-system coredns-74ff55c5b-959p8 1/1 Running 0 3m20s 10.0.0.135 k8s-m01 <none> <none>
kube-system coredns-74ff55c5b-c5hvr 1/1 Running 0 3m20s 10.0.0.197 k8s-m01 <none> <none>
kube-system etcd-k8s-m01 1/1 Running 0 3m20s 10.9.1.11 k8s-m01 <none> <none>
kube-system kube-apiserver-k8s-m01 1/1 Running 0 3m20s 10.9.1.11 k8s-m01 <none> <none>
kube-system kube-controller-manager-k8s-m01 1/1 Running 0 3m20s 10.9.1.11 k8s-m01 <none> <none>
kube-system kube-proxy-9kzw9 1/1 Running 0 3m20s 10.9.1.11 k8s-m01 <none> <none>
kube-system kube-scheduler-k8s-m01 1/1 Running 0 3m20s 10.9.1.11 k8s-m01 <none> <none>
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-m01 Ready control-plane,master 4m44s v1.20.2 10.9.1.11 <none> Ubuntu 20.04.1 LTS 5.4.0-54-generic containerd://1.4.3
Les pods coredns sont maintenant en Running et le noeud k8s-m01 est Ready
Quelques détails sur Cilium
Ajoutons tout d’abord un second noeud au cluster (k8s-w01) et analysons les pods présents :
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-system cilium-cc8zz 1/1 Running 0 110s 10.9.1.21 k8s-w01 <none> <none>
kube-system cilium-hlsmd 1/1 Running 0 13m 10.9.1.11 k8s-m01 <none> <none>
kube-system cilium-operator-66bb9d8b9d-4rgng 1/1 Running 0 13m 10.9.1.11 k8s-m01 <none> <none>
kube-system cilium-operator-66bb9d8b9d-5jm8f 1/1 Running 0 13m 10.9.1.21 k8s-w01 <none> <none>
kube-system coredns-74ff55c5b-959p8 1/1 Running 0 15m 10.0.0.135 k8s-m01 <none> <none>
kube-system coredns-74ff55c5b-c5hvr 1/1 Running 0 15m 10.0.0.197 k8s-m01 <none> <none>
kube-system etcd-k8s-m01 1/1 Running 0 15m 10.9.1.11 k8s-m01 <none> <none>
kube-system kube-apiserver-k8s-m01 1/1 Running 0 15m 10.9.1.11 k8s-m01 <none> <none>
kube-system kube-controller-manager-k8s-m01 1/1 Running 0 15m 10.9.1.11 k8s-m01 <none> <none>
kube-system kube-proxy-7jzh2 1/1 Running 0 110s 10.9.1.21 k8s-w01 <none> <none>
kube-system kube-proxy-9kzw9 1/1 Running 0 15m 10.9.1.11 k8s-m01 <none> <none>
kube-system kube-scheduler-k8s-m01 1/1 Running 0 15m 10.9.1.11 k8s-m01 <none> <none>
Cilium installe deux composants :
- l’agent Cilium (
cilium-xxxx)- est présent sur chaque noeud du cluster (via un
DaemonSet) - est en charge des programmes eBPF injectés dans le noyau Linux servant à contrôler les accès réseaux des conteneurs
- est présent sur chaque noeud du cluster (via un
- l’opérateur Cilium (
cilium-operator-xxxx)- est en charge des opérations globales au cluster (contrairement à l’agent qui se limite au noeud)
Fonctionnalités de base
Depuis chaque agent il est possible d’intéragir avec l’API de Cilium via le client cilium pour par exemple
Connaître l’état de l’agent
$ kubectl exec cilium-cc8zz -n kube-system -- cilium status
KVStore: Ok Disabled
Kubernetes: Ok 1.20 (v1.20.0) [linux/amd64]
Kubernetes APIs: ["cilium/v2::CiliumClusterwideNetworkPolicy", "cilium/v2::CiliumEndpoint", "cilium/v2::CiliumNetworkPolicy", "cilium/v2::CiliumNode", "core/v1::Namespace", "core/v1::Node", "core/v1::Pods", "core/v1::Service", "discovery/v1beta1::EndpointSlice", "networking.k8s.io/v1::NetworkPolicy"]
KubeProxyReplacement: Disabled
Cilium: Ok OK
NodeMonitor: Listening for events on 2 CPUs with 64x4096 of shared memory
Cilium health daemon: Ok
IPAM: IPv4: 2/255 allocated from 10.0.1.0/24,
BandwidthManager: Disabled
Host Routing: BPF
Masquerading: IPTables
Controller Status: 17/17 healthy
Proxy Status: OK, ip 10.0.1.68, 0 redirects active on ports 10000-20000
Hubble: Ok Current/Max Flows: 102/4096 (2.49%), Flows/s: 0.41 Metrics: Disabled
Cluster health: 2/2 reachable (2021-01-31T20:55:43Z)
Afficher les noeuds du cluster
$ kubectl exec cilium-cc8zz -n kube-system -- cilium node list
Name IPv4 Address Endpoint CIDR IPv6 Address Endpoint CIDR
k8s-m01 10.9.1.11 10.0.0.0/24
k8s-w01 10.9.1.21 10.0.1.0/24
On retouve ici les plages d’adressage des pods propres à chaque noeud
Lister les services du cluster
$ kubectl exec cilium-cc8zz -n kube-system -- cilium service list
ID Frontend Service Type Backend
1 10.96.0.1:443 ClusterIP 1 => 10.9.1.11:6443
2 10.96.0.10:9153 ClusterIP 1 => 10.0.0.197:9153
2 => 10.0.0.135:9153
3 10.96.0.10:53 ClusterIP 1 => 10.0.0.197:53
2 => 10.0.0.135:53
Et bien d’autres choses encore…
Voici un petit aperçu des capacités de Cilium.
J’aborderais plus en détails certaines autres fonctionnalitées comme l'observabilité avec Hubble ou la possibilité de mettre en place des règles de firewall au niveau des noeuds dans un prochain article.
Prochaine étape
Avec l’installation d’un plugin CNI nous avons un début de cluster fonctionnel, mais pas encore complétement utilisable.
Avant d’aborder d’autres points tels que le stockage ou la mise en place d’un ingress-controller, je vais faire un retour sur les différents éléments que j’ai appris lors des 2 premières étapes.
Ressources
- Les namespaces Linux
- Network Namespaces Basics Explained in 15 Minutes
- Introduction to Linux interfaces for virtual networking
